GeoHash编码
GeoHash是一种对地理坐标进行编码的方法,它将二维坐标映射为一个字符串。每个字符串代表一个特定的矩形,在该矩形范围内的所有坐标都共用这个字符串。字符串越长精度越高,对应的矩形范围越小。
对一个地理坐标编码时,按照初始区间范围纬度[-90,90]和经度[-180,180],计算目标经度和纬度分别落在左区间还是右区间。落在左区间则取0,右区间则取1。然后,对上一步得到的区间继续按照此方法对半查找,得到下一位二进制编码。当编码长度达到业务的进度需求后,根据”偶数位放经度,奇数位放纬度”的规则,将得到的二进制编码穿插组合,得到一个新的二进制串。最后,根据base32的对照表,将二进制串翻译成字符串,即得到地理坐标对应的目标GeoHash字符串。
以坐标”30.280245, 120.027162“为例,计算其GeoHash字符串。首先对纬度做二进制编码:
将[-90,90]平分为2部分,”30.280245“落在右区间(0,90],则第一位取1。
将(0,90]平分为2分,”30.280245“落在左区间(0,45],则第二位取0。
不断重复以上步骤,得到的目标区间会越来越小,区间的两个端点也越来越逼近”30.280245“。
下图的流程详细地描述了前几次迭代的过程:
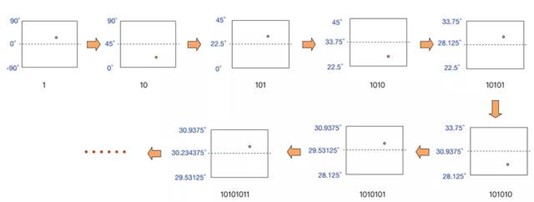
按照上面的流程,继续往下迭代,直到编码位数达到我们业务对精度的需求为止。完整的15位二进制编码迭代表格如下:
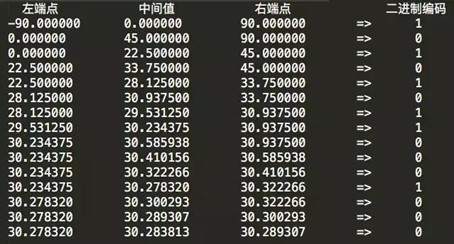
得到的纬度二进制编码为10101 01100 01000。
按照同样的流程,对经度做二进制编码,具体迭代详情如下:
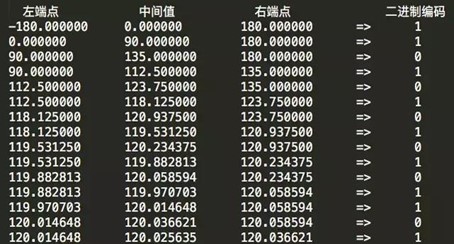
得到的经度二进制编码为11010 10101 01101。
按照”偶数位放经度,奇数位放纬度”的规则,将经纬度的二进制编码穿插,得到完成的二进制编码为:11100 11001 10011 10010 00111 00010。由于后续要使用的是base32编码,每5个二进制数对应一个32进制数,所以这里将每5个二进制位转换成十进制位,得到28,25,19,18,7,2。
对照base32编码表,得到对应的编码为:wtmk72。
可以在geohash.org/网站对上述结果进行验证,验证结果如下:
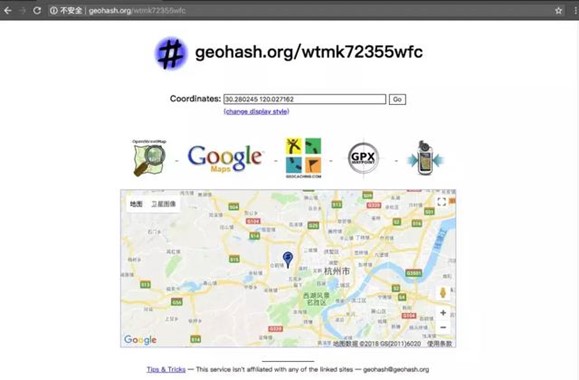
验证结果的前几位与我们的计算结果一致。如果我们利用二分法获取二进制编码时迭代更多次,就会得到验证网站中这样的位数更多的更精确结果。
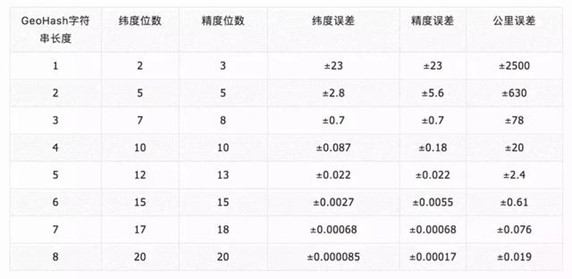
GeoHash字符串的长度与精度的对应关系如下:
面数据GeoHash编码实现
上一节介绍的标准GeoHash算法只能用来计算二维点坐标对应的GeoHash编码,我们的场景中还需要计算面数据(即GIS中的POLYGON多边形对象)对应的GeoHash编码,需要扩展算法来实现。
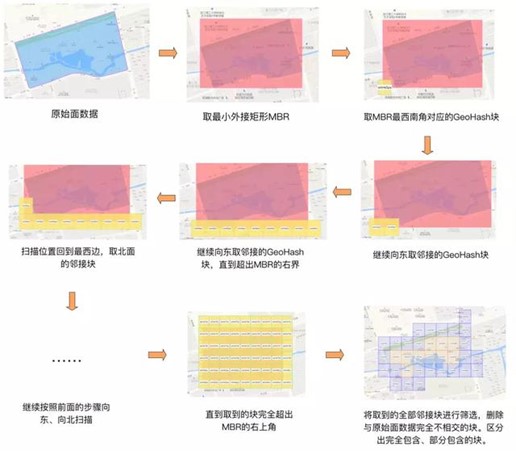
算法思路是,先找到目标Polygon的最小外接矩形MBR,计算此MBR西南角坐标对应的GeoHash编码。然后用GeoHash编码的逆算法,反解出此编码对应的矩形GeoHash块。以此GeoHash块为起点,循环往东、往北找相邻的同等大小的GeoHash块,直到找到的GeoHash块完全超出MBR的范围才停止。如此找到的多个GeoHash块,边缘上的部分可能与目标Polygon完全不相交,这部分块需要通过计算剔除掉,如此一来可以减少后续不必要的计算量。
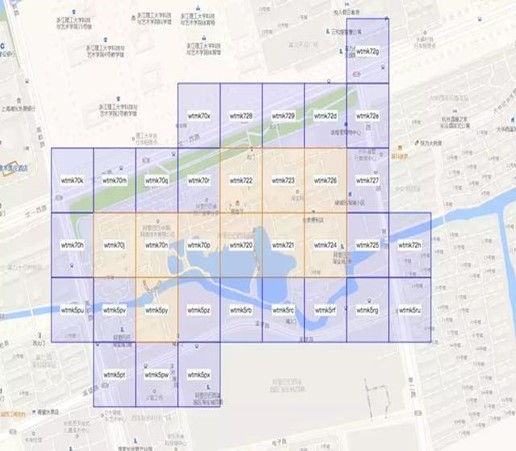
上面的例子中最终得到的结果高清大图如下,其中蓝色的GeoHash块是与原始Polygon部分相交的,橘黄色的GeoHash块是完全被包含在原始Polygon内部的。
上述算法总结成流程图如下:

求临近GeoHash块的快速算法
上一节对面数据进行GeoHash编码的流程图中标记为绿色和橘黄色的两步,分别是要寻找相邻的东边或北边的GeoHash字符串。
传统的做法是,根据当前GeoHash块的反解信息,求出相邻块内部的一点,在对这个点做GeoHash编码,即为相邻块的GeoHash编码。如下图,我们要计算“wtmk72”周围的8个相邻块的编码,就要先利用GeoHash逆算法将“wtmk72”反解出4个顶点的坐标N1、N2、N3、N4,然后由这4个坐标计算出右侧邻接块内部的任意一点坐标N5,再对N5做GeoHash编码,得到的”wtmk78“就是我们要求的右边邻接块的编码。按照同样的方法,求可以求出“wtmk72”周围总共8个邻接块的编码。
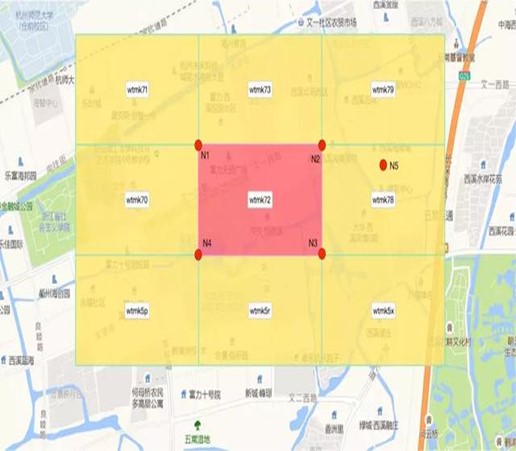
这种方法需要先解码一次再编码一次,比较耗时,尤其是在指定的GeoHash字符串长度较长需要循环较多次的情况下。
通过观察GeoHash编码表的规律,结合GeoHash编码使用的Z阶曲线的特性,验证了一种通过查表来快速求相邻GeoHash字符串的方法。
还是以”wtmk72“这个GeoHash字符串为例,对应的10进制数是”28,25,19,18,7,2“,转换成二进制就是11100 11001 10011 10010 00111 00010。其中,w对应11100,这5个二进制位分别代表”经
纬
经
纬
经”;t对应11001,这5个二进制位分别代表”纬
经
纬
经
纬”。由此推广开来可知,GeoHash中的奇数位字符(本例中的‘w’、‘m’、‘7’)代表的二进制位分别对应”经
纬
经
纬
经”,偶数位字符(本例中的‘t’、‘k’、‘2’)代表的二进制位分别对应”纬
经
纬
经
纬”。
‘w’的二进制11100,转换成方位含义就是”右
上
右
下
左”。‘t’的二进制11001,转换成方位含义就是”上
右
下
左
上”。
根据这个字符与方位的转换关系,我们可以知道,奇数位上的字符与位置对照表如下:

偶数位上的字符与位置对照表如下:

这里可以看到一个很有意思的现象,奇数位的对照表和偶数位对照表存在一种转置和翻转的关系。
有了以上两份字符与位置对照表,就可以快速得出每个字符周围的8个字符分别是什么。而要计算一个给定GeoHash字符串周围8个GeoHash值,如果字符串最后一位字符在该方向上未超出边界,则前面几位保持不变,最后一位取此方向上的相邻字符即可;如果最后一位在此方向上超出了对照表边界,则先求倒数第二个字符在此方向上的相邻字符,再求最后一个字符在此方向上相邻字符(对照表环状相邻字符);如果倒数第二位在此方向上的相邻字符也超出了对照表边界,则先求倒数第三位在此方向上的相邻字符。以此类推。
以上面的”wtmk72“举例,要求这个GeoHash字符串的8个相邻字符串,实际就是求尾部字符’2‘的相邻字符。’2‘适用偶数对照表,它的8个相邻字符分别是’1‘、’3‘、’9‘、’0‘、’8‘、’p‘、’r‘、’x‘,其中’p‘、’r‘、’x‘已经超出了对照表的下边界,是将偶数位对照表上下相接组成环状得到的相邻关系。所以,对于这3个超出边界的”下方”相邻字符,需要求倒数第二位的下方相邻字符,即’7‘的下方相邻字符。’7‘是奇数位,适用奇数位对照表,’7‘在对照表中的”下方”相邻字符是’5‘,所以”wtmk72“的8个相邻GeoHash字符串分别是”wtmk71“、”wtmk73“、”wtmk79“、”wtmk70“、”wtmk78“、”wtmk5p“、”wtmk5r“、”wtmk5x“。利用此相邻字符串快速算法,可以大大提高上一节流程图中面数据GeoHash编码算法的效率。