基于Windows部署Spark3.0.0及联合Hadoop测试
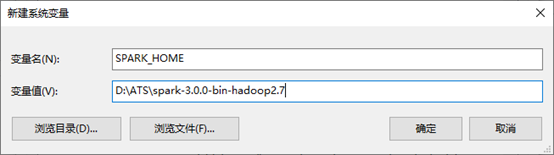
一、配置spark的环境变量, 并将%SPARK_HOME%\bin加入环境变量,完成环境配置。
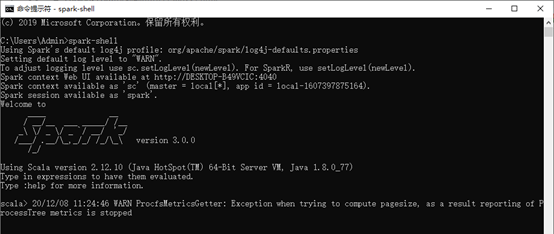
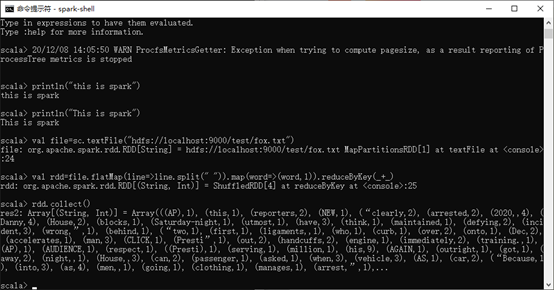
二、启动Spark,cmd输入spark-shell
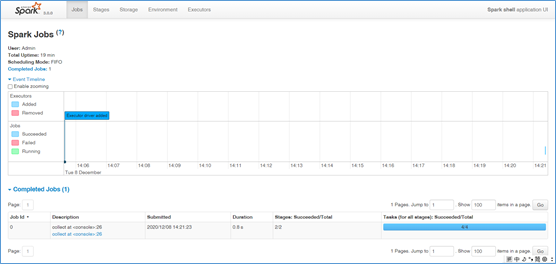
三、访问http://localhost:4040/jobs/
四、Spark联合Hadoop测试
val file=sc.textFile(“hdfs://localhost:9000/test/fox.txt”)
val rdd=file.flatMap(line=>line.split(” “)).map(word=>(word,1)).reduceByKey(_+_)
rdd.collect()
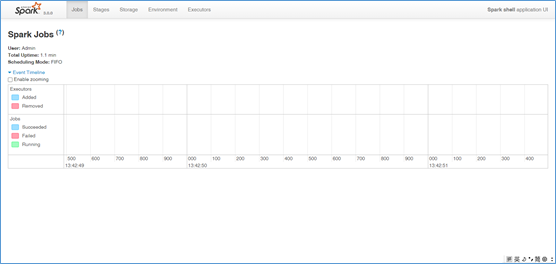
五、查看Spark job